|
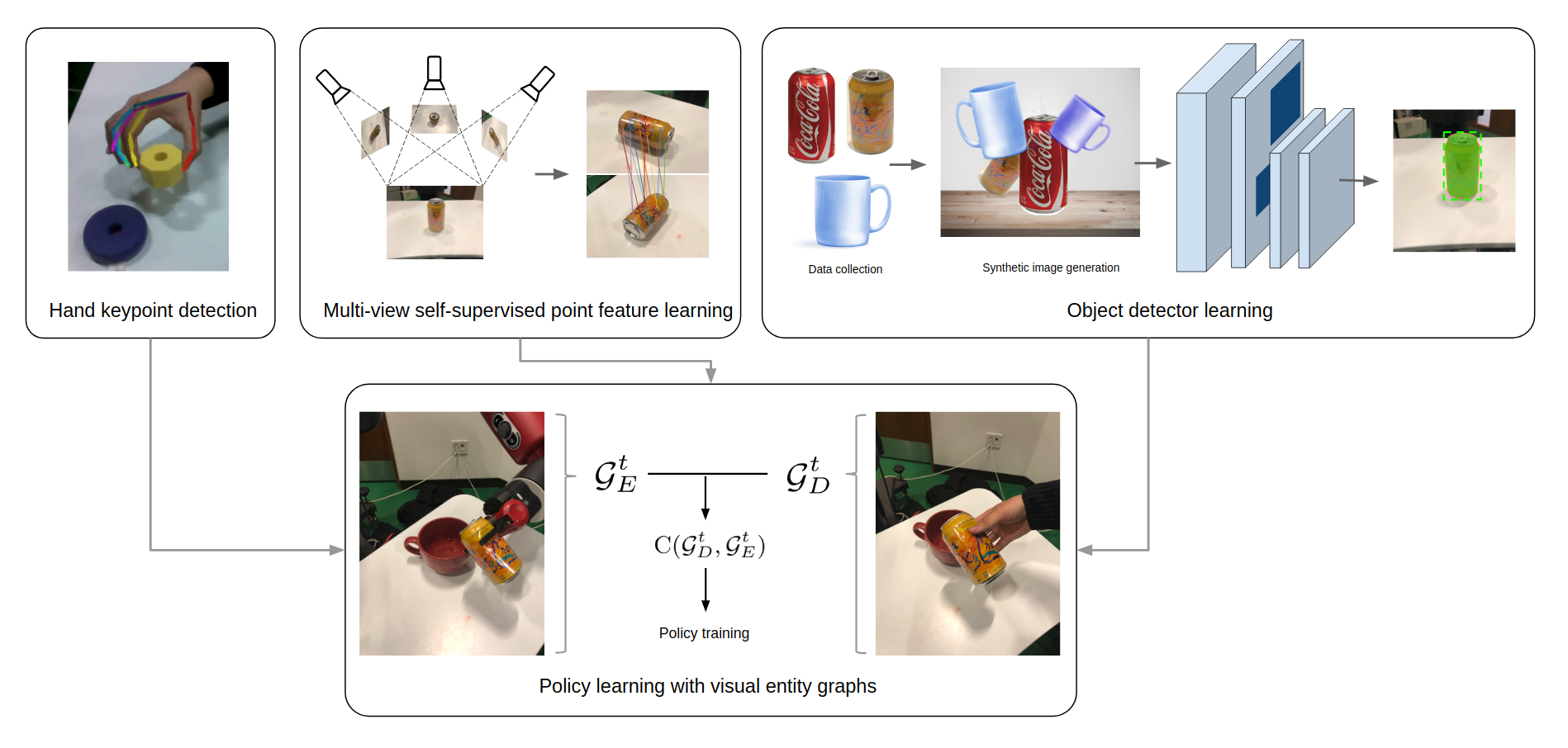
We use human hand keypoint detectors, multi-viewpoint feature learning, and synthetic image generation for on-the-fly object detector training from only a few object mask examples. Using a manually designed mapping between the human hand and the robot, the visual
detectors can effectively bridge the visual gap between demonstrator and imitator environment, are robust to background clutter, and generalize across different object instances.
|